Hello! My name is John, and I’m in the process of building a new tool to examine user music preferences via the Spotify API. This blog will contain an end to end explanation of my development progress and provide weekly updates on functionality. My codebase is pushed to my github regularly if you are interested in trying the app for yourself or want to contribute.
The big idea behind this project is that order matters when creating playlists. DJs and musicians are thoughtful about which songs will be played in what order during a live set, and this framework could be used to enhance a user’s listening experience with their own music. My theory is that DJs have a specific ‘style’ when mixing tracks, and I might be able to capture that thought process via data science and machine learning techniques, then apply it to a user’s musical preferences.
This idea came about over the summer when I started listening to a lot of deep house music. I really enjoy music by Nora en Pure, Adon, and Artlec. Their distinctive style involves piano melodies played on top of a kick drum. Spotify’s Discover weekly was serving me songs in this genre sporadically, and I was curious if I could utilize Spotify’s open source data to identify more songs in this and other sub-genres.
After reading through Spotify’s developer documentation, I found the ‘Audio Features’ endpoint to be a good starting point. With guidance from several open source projects here, here and here, I created a Spotify client library to retrieve this data on the songs in my playlists. I opted to write my own client in order to learn the fundamentals of OAuth and create methods that would work well for my use cases. I implemented the authorization flow described here via a Python/Flask application as it is a lightweight framework that can scale as needed.
The data I pulled contained several attributes about each song, including loudness, tempo, key, and 7 audio features such as valence, energy, and instrumentalness. In my understanding, these 7 features are generated via machine learning, with a human ‘tastemaker’ choosing example songs with a value of 1 (100%) and a value of 0 on each attribute, and letting the algorithm interpolate the values between 0 and 1 for each song. My initial thought was to implement a logistic regression using these values as the inputs, and a 1 or 0 if the song should fall into my ‘Upbeat Piano’ subgenre playlist. While I was able to set up the problem using Sklearn and pandas, I wasn’t able to get meaningful results as the sample size was too small. Rather than manually searching for new music and labeling it, I decided it would be better to automate this discovery process and come back to this problem later on.
In undergrad, I worked with open source data from the City of Boston in one of my computer science classes, and implemented the k-means algorithm. In short, this algorithm finds clusters in a dataset by setting a set number (k) of centers randomly in the dataset, and assigning observations to the closest center, and moving the centers to minimize total distance between any observation and its assigned center. I was impressed by how powerful an unsupervised learning algorithm could be, and thought it might work well to find patterns in this dataset. We can think of each song as a location in 7 dimensional space, and allow sklearn’s k-means algorithm to group the data points. We can then map the cluster assignments back to the songs, and create new playlists in the users library, which should be musically similar.
I ran this implementation on several of my playlists, and was surprised when one resulting playlist contained only 5 songs, compared to others that contained as many as 50 songs. Upon further investigation, the playlist with 5 songs contained only tracks with vocal overlay from a DJ radio show introducing the next song to be played. This was a bit of a eureka moment as it showed that the data can be extremely precise. I also noticed that running the algorithm on similar music allowed me to identify extremely niche sub-genres.
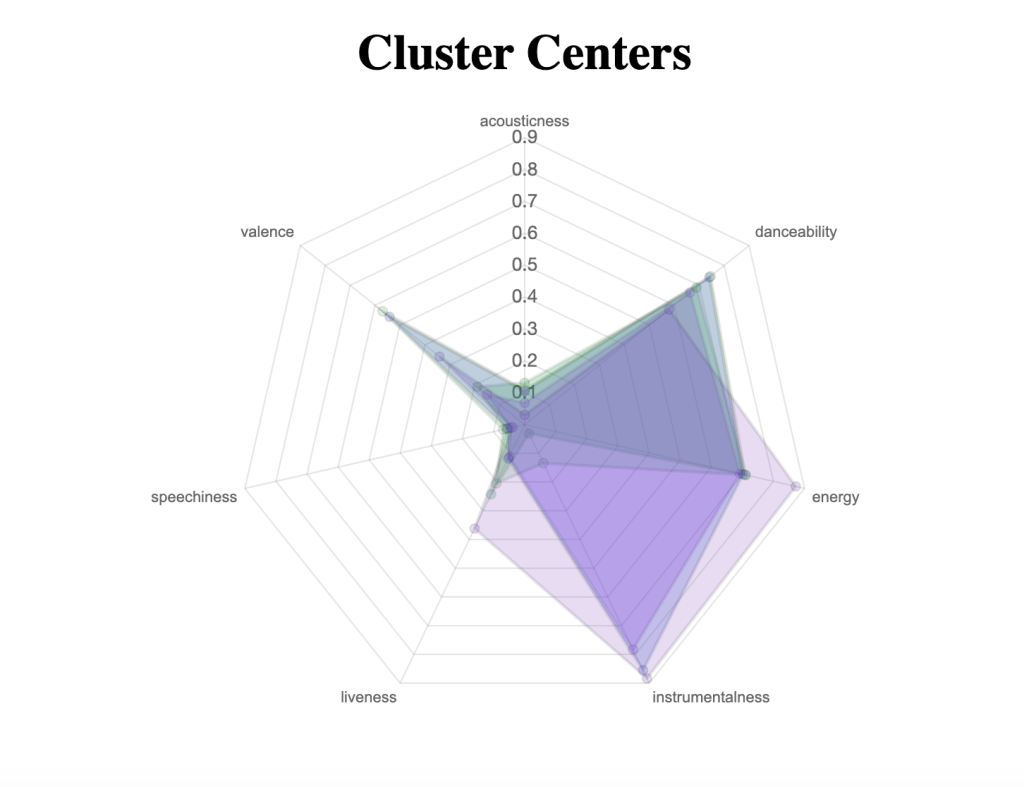
At this stage, I needed a visualization of the results to illustrate what made one cluster different from another. I chose to use a radar chart to display the resulting cluster center attributes in a way that illustrated all 7 dimensions, effectively thinking about each cluster as a shape.
This led me to the idea for DJ set pattern discovery. If we think about each song as a 7 sided shape dictated by the values of its Spotify music features, then put a number of songs in order, we create a ‘tunnel’ that changes in shape as you progress through the set. Theoretically, I would expect some attributes to change throughout the set, maybe energy and valence are the ‘driving’ factors in the set, and ‘instrumentalness’ stays fairly constant, or doesn’t exhibit a pattern. Framing each DJ set as a tunnel captures a large volume of data in an easily consumed model, and should illustrate DJ style to a user with no background in music theory.
I believe the order decisions can be framed as a ratio of one song to another, for example ‘energy’ might increase by 10% each song until it peaks at some value, then declines to the end of the set. If this holds true, I can apply these ratios to a users songs to create a set with their own music. Utilizing Spotify’s recommendation functionality will allow users to discover new music they might like, in the same context as a DJ mixing a new track into their set.
I believe different DJs will have different styles, and scraping sets from a variety of artists will result in different archetypes I can offer the user as options, something along the lines of ‘lounge’ vibe all the way up to ‘festival.’ I’m currently working to import DJ sets programmatically to build a robust training dataset. I’m also working on the recommendation functionality that creates a pool of tracks to build the final playlist from. Ultimately, the goal is to pull a user’s recent top listens, and use that to create a custom set using one of the archetypes from my training dataset. The user would then be able to adjust the set via control points at each point in the tunnel, for example boosting the energy level in the 3rd track. This would fetch another song from the pool that was a better fit in that slot, and the rest of the set would readjust accordingly.
This is still a work in progress, and I am always eager to hear new perspectives and ideas on use cases and implementations. If any of this piques your interest, I would love to connect. I can be reached at jtdjproject@gmail.com
